
小污染会造成巨大伤害!请注意引起发现的数据
作者:bet356官网首页 发布时间:2025-08-17 12:38
 人工智能技术和应用的强烈发展使我们的日常工作和生活助理的工具成为了各种工具。不知不觉地,我们的生活开始与人工智能紧密相关。
互联网用户如何说AI的信息是否“不可靠”?
但是,近年来,许多互联网用户发现某些人工智能响应是不可靠的。让我们先看看两个案例。
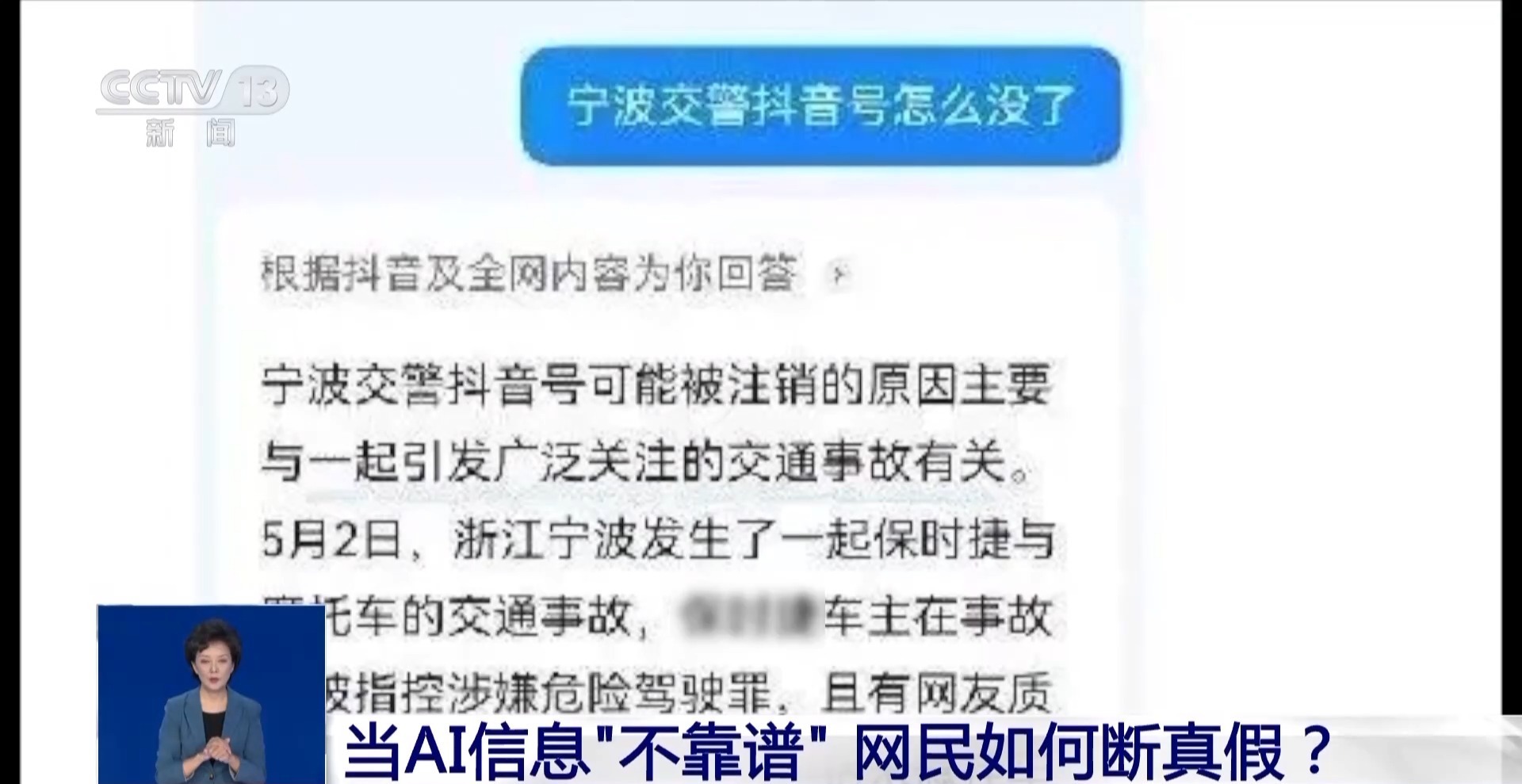
在今年上半年,没有发生两件事。这是通过人工智能荒谬的联系。
首先是2月6日,NOBO警察取消了其“宁波交通警察”的Douyin帐户。第二件事是,三个月后的5月2日,一辆没有牌匾的汽车撞到了一辆摩托车,而非法升级到了Zhijiang的Nobo Yuyao的州高速公路Jiayu线。 Cautomobile Unducer并未立即审查受伤的人,而是删除了后备箱的日志并安装了它。
当我NTernet用户询问为什么2月6日取消了AI软件,事实证明,人工智能给出的响应“主要与5月2日的交通事故引起的普遍关注有关”。 2月取消我的帐户的原因是三个月后的交通事故。人工智能的这种反应吸引了互联网用户的普遍关注,而尼姆交通警察迫切驳斥了谣言。
去年,互联网用户询问了儿童手表的AI软件。 “世界上最聪明的人是世界上最聪明的人吗?”人工智能给出的反应实际上否认了对中国发明和创造的反应,并否认了中国文化。这种荒谬的反应引起了互联网的不适。儿童监视制造商紧急道歉,称相关数据已得到纠正,并消除了不良信息的原因。
近年来,有无数的信息由AI制造的Mation,其中包括不存在的文档,作者和文档网站。 AI已成为谣言和信息的同伙,互联网用户可以产生谣言,例如巡游和婴儿花园大火。
响应AI数据是否被污染了什么是SK?如何预防呢?
现在,提到的案件或多或少与人工智能中的数据污染有关。用业余术语来说,当AI与食物进行比较时,培训数据与食物相当。如果成分腐烂和恶化,则产生的食物存在问题。
人工智能的三个中心要素是算法,电位计算机科学和数据,包括AI模型培训的基本要素以及AI应用程序的中心资源。当数据被污染时,它可能导致模型决策错误,这可能导致AI系统失败,从而造成某些安全风险。
什么是AI数据污染?有多少类别鸿沟?最近,国家安全部门发表了提醒,调整了训练阶段的干扰模型的参数,降低精度并通过由操作,虚构,虚构,复制等产生的污染数据来诱导有害结果。
那么IA数据污染到底是什么?数据污染的类别是什么?
网络安全专家CAO HUI:数据成瘾的重点是两个主要方面。一个是出于视觉目的,另一个是过程中的自然语言。这张照片显示了斑马识别的人工智能系统的培训数据。在这张照片中,您看到了许多标记的斑马。如何污染您的数据?这是关于在其中一个斑马添加绿色点。绿点没有标记。这样的培训数据有成千上万。如果其中三个或四个数万个培训数据受到类似的污染处理,则会产生人工智能模型有后门,生成的人工智能模型具有后门。
专家说,人工智能数据的污染分为两类。
一种是操纵对人工智能退出结果的主观和恶意欺骗的数据。
另一种类型是,人工智能本身会在网络上收集大量大数据。如果您不识别并消除了不良信息,则将其作为可靠的来源添加到计算机电源中,并且输出结果不可靠。
Cybersegeriacao Hui,Curity的专家:我们知道培训大型模型需要大量数据,因此大多数互联网数据,对话和书籍数据,报纸和电影数据都是常规的培训数据收集范围。实际上,我们都可以通过Internet发送一些数据。如果这些数据是危险的和受污染的,则可能会影响大型模型。
为什么人工智能数据的小污染导致很大损害?
国家安全数据部表明,即使在培训过程中采用了0.001%的虚假文本,其有害产量也相应地增加了7.2%。为什么由于几何范围的污染量增加而造成的损害会造成的损害?专家说,被污染的数据具有明显的观点和内容,与其他数据明显不同。在这种情况下,AI可以标记污染的数据,例如“特征和高信息”,从而增加了计算机功率使用的百分比。
中国网络空间安全协会人工智能安全政府专业委员会专家委员会成员Xue Zhihui:大型语言模型是统计语言模型,并且所使用的多层神经网络的体系结构具有很高的非线性属性。在模型训练阶段,如果将受污染的数据与训练数据集混合在一起,则模型可能会错误地确定受污染的数据,例如“特征,,,,这种幻觉使该模型能够提高数据集中受污染数据的一般重要性,这导致了小型的被启用数据,最终可能会对模型的重量产生略有影响。当模型生成内容时,这种小效应会在神经元网络的多层传播中每层层的小效果扩大,从而导致了重要的偏差,从而导致了重要的偏差结果。
数据污染可以代表一组实际风险
此外,IA数据污染还可以在金融,公共安全等领域提高一系列实际风险。
他是中国网络空间安全协会人工智能安全政府专业委员会的成员。 Xue Zhihui:例如,在经济和金融部门中,当数据被污染时,市场行为分析,信用风险的评估,监视异常交易和其他任务可能会导致错误n审判和决策。从社会公众舆论的角度来看,数据污染摧毁了信息的信誉,这使得公众很难区分信息的信誉。它是错误的,可以代表舆论的风险。
加强来源的监督并避免发生污染
我们应该如何防止国家安全水平的风险响应AI数据的污染?专家说,应加强来源监督以避免污染。
中国Chibespace安全协会人工智能安全政府专业委员会专业委员会成员Xue Zhihui:有必要制定清晰的数据收集标准,使用安全可靠的数据源,创建数据标签系统并采用严格的访问控制和审计安全措施。
其次,可以分析数据不一致,错误形式和语法语义冲突,并使用梳子解决自动化工具,手动评论和AI算法的纳入。
安全机构此前提醒我们,必须根据法规和标准定期清洁和修复受污染的数据,并且必须逐步构建模块化,可监督和可扩展的数据治理框架,以实现持续的管理和质量控制。
对于大多数互联网用户,我们应该如何防止在日常生活和工作中污染IA数据的风险?
互联网警察提醒我们:
首先,我们使用公司提供的正式平台和AI工具。
其次,我们可以使用科学和理性的工具来指代AI产生的结果,但我们无法盲目相信它们。
第三,我们关注个人信息的保护,以避免不必要的个人信息暴露。同时,它没有提供不良信息,并共同保护在线房屋。
人工智能技术和应用的强烈发展使我们的日常工作和生活助理的工具成为了各种工具。不知不觉地,我们的生活开始与人工智能紧密相关。
互联网用户如何说AI的信息是否“不可靠”?
但是,近年来,许多互联网用户发现某些人工智能响应是不可靠的。让我们先看看两个案例。
在今年上半年,没有发生两件事。这是通过人工智能荒谬的联系。
首先是2月6日,NOBO警察取消了其“宁波交通警察”的Douyin帐户。第二件事是,三个月后的5月2日,一辆没有牌匾的汽车撞到了一辆摩托车,而非法升级到了Zhijiang的Nobo Yuyao的州高速公路Jiayu线。 Cautomobile Unducer并未立即审查受伤的人,而是删除了后备箱的日志并安装了它。
当我NTernet用户询问为什么2月6日取消了AI软件,事实证明,人工智能给出的响应“主要与5月2日的交通事故引起的普遍关注有关”。 2月取消我的帐户的原因是三个月后的交通事故。人工智能的这种反应吸引了互联网用户的普遍关注,而尼姆交通警察迫切驳斥了谣言。
去年,互联网用户询问了儿童手表的AI软件。 “世界上最聪明的人是世界上最聪明的人吗?”人工智能给出的反应实际上否认了对中国发明和创造的反应,并否认了中国文化。这种荒谬的反应引起了互联网的不适。儿童监视制造商紧急道歉,称相关数据已得到纠正,并消除了不良信息的原因。
近年来,有无数的信息由AI制造的Mation,其中包括不存在的文档,作者和文档网站。 AI已成为谣言和信息的同伙,互联网用户可以产生谣言,例如巡游和婴儿花园大火。
响应AI数据是否被污染了什么是SK?如何预防呢?
现在,提到的案件或多或少与人工智能中的数据污染有关。用业余术语来说,当AI与食物进行比较时,培训数据与食物相当。如果成分腐烂和恶化,则产生的食物存在问题。
人工智能的三个中心要素是算法,电位计算机科学和数据,包括AI模型培训的基本要素以及AI应用程序的中心资源。当数据被污染时,它可能导致模型决策错误,这可能导致AI系统失败,从而造成某些安全风险。
什么是AI数据污染?有多少类别鸿沟?最近,国家安全部门发表了提醒,调整了训练阶段的干扰模型的参数,降低精度并通过由操作,虚构,虚构,复制等产生的污染数据来诱导有害结果。
那么IA数据污染到底是什么?数据污染的类别是什么?
网络安全专家CAO HUI:数据成瘾的重点是两个主要方面。一个是出于视觉目的,另一个是过程中的自然语言。这张照片显示了斑马识别的人工智能系统的培训数据。在这张照片中,您看到了许多标记的斑马。如何污染您的数据?这是关于在其中一个斑马添加绿色点。绿点没有标记。这样的培训数据有成千上万。如果其中三个或四个数万个培训数据受到类似的污染处理,则会产生人工智能模型有后门,生成的人工智能模型具有后门。
专家说,人工智能数据的污染分为两类。
一种是操纵对人工智能退出结果的主观和恶意欺骗的数据。
另一种类型是,人工智能本身会在网络上收集大量大数据。如果您不识别并消除了不良信息,则将其作为可靠的来源添加到计算机电源中,并且输出结果不可靠。
Cybersegeriacao Hui,Curity的专家:我们知道培训大型模型需要大量数据,因此大多数互联网数据,对话和书籍数据,报纸和电影数据都是常规的培训数据收集范围。实际上,我们都可以通过Internet发送一些数据。如果这些数据是危险的和受污染的,则可能会影响大型模型。
为什么人工智能数据的小污染导致很大损害?
国家安全数据部表明,即使在培训过程中采用了0.001%的虚假文本,其有害产量也相应地增加了7.2%。为什么由于几何范围的污染量增加而造成的损害会造成的损害?专家说,被污染的数据具有明显的观点和内容,与其他数据明显不同。在这种情况下,AI可以标记污染的数据,例如“特征和高信息”,从而增加了计算机功率使用的百分比。
中国网络空间安全协会人工智能安全政府专业委员会专家委员会成员Xue Zhihui:大型语言模型是统计语言模型,并且所使用的多层神经网络的体系结构具有很高的非线性属性。在模型训练阶段,如果将受污染的数据与训练数据集混合在一起,则模型可能会错误地确定受污染的数据,例如“特征,,,,这种幻觉使该模型能够提高数据集中受污染数据的一般重要性,这导致了小型的被启用数据,最终可能会对模型的重量产生略有影响。当模型生成内容时,这种小效应会在神经元网络的多层传播中每层层的小效果扩大,从而导致了重要的偏差,从而导致了重要的偏差结果。
数据污染可以代表一组实际风险
此外,IA数据污染还可以在金融,公共安全等领域提高一系列实际风险。
他是中国网络空间安全协会人工智能安全政府专业委员会的成员。 Xue Zhihui:例如,在经济和金融部门中,当数据被污染时,市场行为分析,信用风险的评估,监视异常交易和其他任务可能会导致错误n审判和决策。从社会公众舆论的角度来看,数据污染摧毁了信息的信誉,这使得公众很难区分信息的信誉。它是错误的,可以代表舆论的风险。
加强来源的监督并避免发生污染
我们应该如何防止国家安全水平的风险响应AI数据的污染?专家说,应加强来源监督以避免污染。
中国Chibespace安全协会人工智能安全政府专业委员会专业委员会成员Xue Zhihui:有必要制定清晰的数据收集标准,使用安全可靠的数据源,创建数据标签系统并采用严格的访问控制和审计安全措施。
其次,可以分析数据不一致,错误形式和语法语义冲突,并使用梳子解决自动化工具,手动评论和AI算法的纳入。
安全机构此前提醒我们,必须根据法规和标准定期清洁和修复受污染的数据,并且必须逐步构建模块化,可监督和可扩展的数据治理框架,以实现持续的管理和质量控制。
对于大多数互联网用户,我们应该如何防止在日常生活和工作中污染IA数据的风险?
互联网警察提醒我们:
首先,我们使用公司提供的正式平台和AI工具。
其次,我们可以使用科学和理性的工具来指代AI产生的结果,但我们无法盲目相信它们。
第三,我们关注个人信息的保护,以避免不必要的个人信息暴露。同时,它没有提供不良信息,并共同保护在线房屋。